2.5. Обработка и анализ результатов маркетинговых исследований
Классический метод создания исследуемой выборки - случайный отбор.
Для исследований потребителей обычно используется список избирателей, из которого набирается выборка по случайным цифрам или "каждый первый". Объем выборок обычно порядка нескольких сотен или тысяч (например, для Англии обычно берется около 30000, т.е. примерно тысячная часть взрослого населения).При принятии нормального закона распределения среднеквадратичное отклонение определяется так:
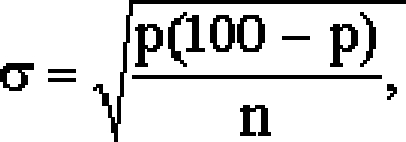
где p - процент популяции, имеющий признак, подлежащий измерению; n - объем выборки.
Например, в выборку включены 10000 домовладельцев и мы нашли, что 10% из них соответствуют измеряемому признаку, тогда
о = . —1 = 0,3%
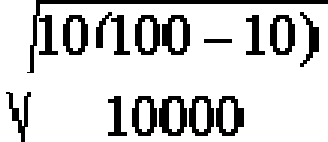
Это означает, что с вероятностью 68% (одно стандартное отклонение) можно утверждать, что результат лежит между 9,7 и 10,3%, а при допустимой вероятности 0,95 - между 9,4 и 10,6% (два о), а если п = 400, то в последнем случае границы 7-13% (стандартное отклонение 1,5%). Поэтому часто принимают необходимый объем выборки в 1000 респондентов (см. табл. 2.9).
Очевидно, что абсолютный уровень ошибки - наивысший при p=50%, например, при n = 400 и допустимой вероятности правильного ответа 0,95 <^=2,5% и границы действительных результатов 45-55%.
Иными словами, чем меньше ясно респондентам решение (50/50 - наихудший вариант), тем меньше точность. В этих случаях надо увеличивать выборку(увеличение выборки в два раза приводит к увеличению точности в V*2 раза). Еще раз следует подчеркнуть, что эти оценки справедливы для действительно случайной выборки.
Таблица 2.9\r\nРазмер выборки Ожидаемый результат (%) при уровне согласия 0,95\r\n 10 или 90 (±) 30 или 70 (±) 50 (±)\r\n50 9 (4,5) 13 (6,5) 14 (7)\r\n100 6 (3) 9 (4,5) 10 (5)\r\n200 4 (2) 6 (3) 7 (3,5)\r\n500 3 (1,5) 4 (2) 4 (2)\r\n1000 2 (1) 3 (1,5) 3 (1,5)\r\n5000 1 (0,5) 1 (0,5) 1 (0,5)\r\nДиапазоны точности при различных объемах выборки
Собранные статистические данные могут анализироваться различным образом. Например, с использованием многомерного регрессионного анализа, факторного анализа, кластерного анализа и анализа связей.
При кластерном анализе ищутся факторы, по которым одни группы потребителей сильно отличаются от других, таким образом, один кластер изолируется от других вследствие "внутреннего сцепления". Это можно продемонстрировать графически (рис. 11).
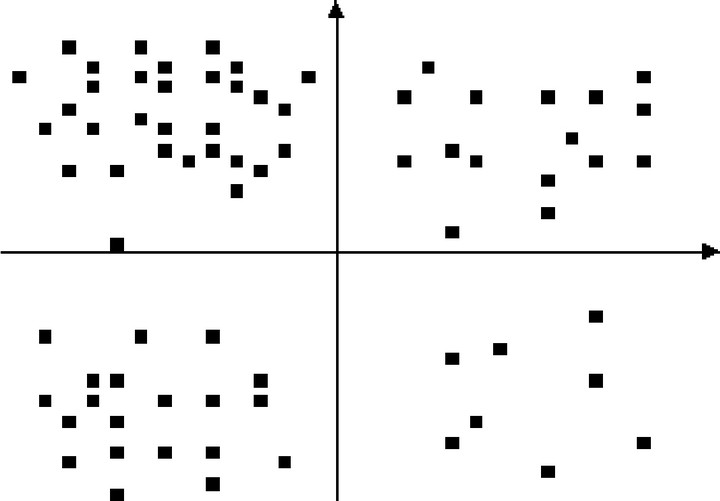
Рис. 11. Типичные результаты кластерного анализа
Кластеры, представленные большей плотностью точек, могут быть нанесены на двухкоординатную плоскость. Таким образом, идентифицируются группы, сегменты и т.д., имеющие некоторые общие характеристики (возраст, нужды, положение и т.д.). Особенно важна эта техника для сегментации рынка, сначала для определения переменных, по которым возникает дифференциация, а затем для дифференциации выборок при исследованиях.
Основные математические процедуры, применяемые при маркетинговых исследованиях, приведены на рис.12 [22].

